最近在看搜索引擎相关的内容,总结分享一下。
搜索引擎,比如我们所常用的Google、百度,还有我们在某些软件或者网站里面使用的搜索框,大致后台的支撑都是这类技术,只是数据量和效果要求不一样,技术复杂度也不一样。
需求和目标 #
需求很明确,就是用户输入一些条件,搜索引擎能够快速反馈用户期望的结果。
这也是搜索引擎的两个主要目标:
- 效果(质量):对于一个用户查询,希望能够检索到最多的相关文档
- 效率(速度):尽可能快地处理用户的查询
要满足这些需求,搜索引擎一般要提供一个最直观交互功能,数据查询,就是我们在Google上面看到的那个搜索框。但是在这个搜索框的背后,还需要数据支撑,那么就需要数据的采集、转换、存储、排序。
这个背后的过程,简单说就是,找数据、读数据、存数据、处理数据。再加上前面提到的查询数据,就差不多了。
下面我们来简单看一下。
数据采集-爬虫 #
找数据、读数据就是数据采集要干的事情。
我们在Google上,能通过关键字搜索到某个网站或者某个博客,然后点击链接就能跳转过去。这个过程就需要Google把这些网站(网页)的信息抓取下来。一般是通过爬虫技术。
简单理解,爬虫的功能就是
- 下载网页
- 发现URL
下载网页好理解。
发现URL可以这么简单理解,就是处理网页中的内容,把URL识别出来,看个例子

这是github某网页的部分内容,爬虫把这个网页下载下来之后,会识别其中的超链接,然后使用GET请求验证一下是否有效,再把有效的URL提取出来。
当然实际的情况比这要复杂得多,这里只是一个简单理解的例子,过程类似。
**数据清洗/**存储 #
找数据、读数据被爬虫解决了,后面自然要存起来。
对于互联网搜索引擎来讲,数据是海量的,存储技术要求不一样。像Google自己的Bigtable,具体不知道是用的什么了,开源的HBase也可以,很多互联网公司有自己研发的分布式存储、分布式文件系统来存。
对于我们自己要搞一个demo,也许Linux文件系统就行了,做个元数据管理服务什么的。这些都是要看数据量,目标能存起来读出来就行了。
存之前,可能要做一些数据清洗,比如过滤掉一些无效的数据,修改些格式啥的。大家可能会叫这个过程是ETL,数据加载清洗转换。
倒排索引 #
数据存起来之后,要能被快速检索到,通过关键字这类的,不可能每次查询都来遍历存储吧。那么就需要另外一些技术手段了。
为了提升查询效率,一般用倒排索引技术,把数据由“文档-词项”信息流转换成“词项-文档”信息存起来,通过词项就能快速定位到文档(数据)。
简单理解倒排索引,大概是这样的。
简化一下,有几个文档,每个文档只有一行字符串:
文档A:This is a book
文档B:This is a cat
文档C:Here is a cat
那么通过分词程序,把这些文档内容提取出来拆分成这样
文档A:This,is,a,book
文档B:This,is,a,book
文档C:Here,is,a,cat
然后逻辑上转换成这样(词项-词频-文档信息)
This,2,[文档A,文档B]
is,3,[文档A,文档B,文档C]
a,3,[文档A,文档B,文档C]
Here,1,[文档C]
book,2,[文档A,文档B]
cat,1,[文档C]
然后查询This的时候,匹配到
This,2,[文档A,文档B]
再根据一些算法,把文档A和文档B排序反馈出去。
如果查询is,可能匹配到
This,2,[文档A,文档B]
is,3,[文档A,文档B,文档C]
这个时候,可能会把文档A、文档B、文档C都反馈出去。
搜索排序 #
关于排序这块,搜索引擎一般叫评分机制,估计是核心技术了。像我们觉得Google比百度要准一些,就是因为评分算法不一样。
评分机制,实际上是在检索模型计算一种相似度,检索模型有向量空间模型、概率模型。
所以基于上面这个例子,比如搜索is,也许会反馈包含This的文档。
在百度搜索拼音“pingguo”,会给出相应汉字“苹果”的搜索结果?是类似的,另一种“相似度”。
评分机制,最简单的是基于词频的,如果是基于这个算法看上面那个例子:
第二次的搜索“is”,反馈顺序,文档C应该是最靠后的。
还有一种检索模型,布尔模型,这种不基于评分,就是对于关键字做是或者否的匹配判定。对于一些数据库系统的字段查询,都是类似这种。
如果基于这种模型,针对上面的例子,搜索“is”,就不会出现只包含“This”的文档了。
分词 #
上面讲倒排索引,过程中会用到分词算法,目的就是把文本拆分成一堆词项。
比如上面的例子是基于空格,将英文句子拆分成英文单词。
当然如果是中文,“我是一个中国人”,上面这种算法就不行了,需要另外的算法。比如基于某个中文词库,将这些词项匹配拆分出来成为:“我”,“是”,“一个”,“中国”,“中国人”,“人”…..
基本过程就是类似这样了,然后还是按照这些词项,做倒排索引。
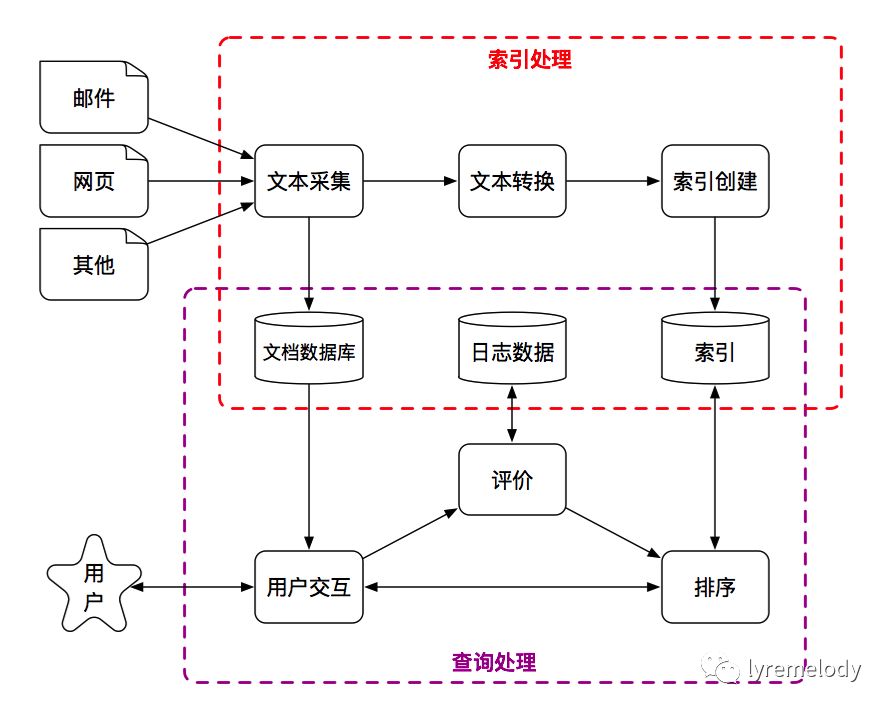
总结基本架构 #
搜索引擎,还涉及到一个搜索评价的问题,这些都会通过日志记录下来,通过分析这些内容,开发者能够对搜索引擎调优算法和性能。
基本上这些就是搜索引擎的一些基本内容了,可以了解个大概,但是,冰山下面的内容还有太多了。
总结一下,搜索引擎主要是效果和效率两个需求和目标,主要会提供索引处理和查询处理两个功能。
根据效果和效率这两个目标而设计的顶层架构,及数据处理流程一般是这样的: