最近在研究Lucene的时候发现了一个数据结构“Trie”,又称为前缀树或字典树。
定义 #
根节点对应空字符串,节点中的位置决定键,关键节点存对应值(比如叶子节点,或者中间某节点)。
以字符为例,一个单词过来比如“tea”,将’t’,’e’,’a’依次存到树中,并给’a’的值+1(‘t’和‘e’的值为0)。
形如:
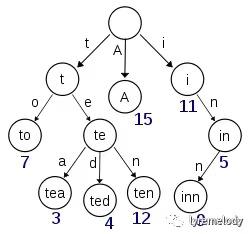
注:图中各节点应该是字符,比如 “to”实际存的是“o”,为了方便看所以写
成“to”。“te”、“tea”、“ted”等同理。
应用场景 #
搜索提示 #
- 当输入一个网址,可以自动搜索出可能的选择
词频统计 #
- 比如统计一个文本出现各单词的个数,通过空格、回车换行等分割出单词,基于字母构建一棵trie树,然后遍历这棵树,输出有值的结点
- 还比如,统计子域名访问次数,也是可以用类似的方法,如blog.lyremelody.org,将”.”分割的词作为节点构建一棵trie树
当然,对于词频统计,数量小,或者内存大的话,直接用二维数组存起来也是可以的。